Learning Weights for the Draco Model#
In this example, we are using a linear SVM model to learn weights for a Draco model. The input to the model are pairs of visualizations where one visualization is preferred to another. We then try to find weights such that most of the pairs are correctly classified. Each visualization is represented as a vector of number of violations.
Given pairs of preferred (positive) \(\lbrack u_1, u_2, ..., u_k \rbrack\) and a not preferred (negative) \(\lbrack v_1, v_2, ..., v_k \rbrack\) visualization, we try to maximize the distance between these vectors using \({\arg\max}_w \sum_{i\, \in\, 0...k} w_i \, (u_i-v_i)\). To implement this loss, we subtract the positive and negative vectors and learn weights using a linear SVM with one class.
import json
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from draco.data_utils import pairs_to_vec
from draco.learn import train_model
from sklearn.decomposition import PCA
from draco import Draco
default_draco = Draco()
def train_and_plot(data: pd.DataFrame, test_size: float = 0.3):
"""use SVM to classify them and then plot them after projecting X, y into 2D using PCA"""
X = data.negative - data.positive
pca = PCA(n_components=2)
X2 = pca.fit_transform(X)
clf = train_model(X, test_size)
# for plotting
X0, X1 = X2[:, 0], X2[:, 1]
xx, yy = make_meshgrid(X0, X1)
f, ax = plt.subplots(figsize=(8, 6))
# predictions made by the model
pred = clf.predict(X)
correct = pred > 0
plt.scatter(
X0[correct],
X1[correct],
c=["green"],
alpha=0.5,
marker=">",
label="correct",
)
plt.scatter(
X0[~correct],
X1[~correct],
c=["red"],
alpha=0.5,
marker="<",
label="incorrect",
)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xlabel("X0")
ax.set_ylabel("X1")
ax.set_xticks(())
ax.set_yticks(())
plt.title("Predictions of Linear Model")
plt.annotate(
f"Score: {clf.score(X, np.ones(len(X))):.{5}}. N: {int(len(data))}",
(0, 0),
(0, -20),
xycoords="axes fraction",
textcoords="offset points",
va="top",
)
plt.legend(loc="lower right")
plt.axis("tight")
plt.show()
return clf
def project_and_plot(data: pd.DataFrame, test_size: float = 0.3):
"""Reduce X, y into 2D using PCA and use SVM to classify them
Then plot the decision boundary as well as raw data points
"""
X = data.negative - data.positive
pca = PCA(n_components=2)
X = pca.fit_transform(X)
clf = train_model(X, test_size)
# for plotting
X0, X1 = X[:, 0], X[:, 1]
xx, yy = make_meshgrid(X0, X1)
f, ax = plt.subplots(figsize=(8, 6))
plot_contours(ax, clf, xx, yy)
# predictions made by the model
pred = clf.predict(X)
correct = pred > 0
plt.scatter(
X0[correct],
X1[correct],
c=["g"],
alpha=0.5,
marker=">",
label="correct",
)
plt.scatter(
X0[~correct],
X1[~correct],
c=["r"],
alpha=0.5,
marker="<",
label="incorrect",
)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xlabel("X0")
ax.set_ylabel("X1")
ax.set_xticks(())
ax.set_yticks(())
plt.title("Predictions of Linear Model")
plt.annotate(
f"Score: {clf.score(X, np.ones(len(X))):.{5}}. N: {int(len(data))}",
(0, 0),
(0, -20),
xycoords="axes fraction",
textcoords="offset points",
va="top",
)
plt.legend(loc="lower right")
plt.axis("tight")
plt.show()
return clf
def plot_contours(ax, clf, xx, yy, **params):
"""Plot the decision boundaries for a classifier.
Params:
ax: matplotlib axes object
clf: a classifier
xx: meshgrid ndarray
yy: meshgrid ndarray
params: dictionary of params to pass to contourf, optional
"""
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
out = ax.contourf(xx, yy, Z, **params)
return out
def make_meshgrid(x, y, h=0.01):
"""Create a mesh of points to plot in
Params:
x: data to base x-axis meshgrid on
y: data to base y-axis meshgrid on
h: stepsize for meshgrid, optional
Returns:
xx, yy : ndarray
"""
x_min, x_max = x.min() - 1, x.max() + 1
y_min, y_max = y.min() - 1, y.max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
return xx, yy
learn_data = {}
with open("./data/saket2018_draco2.json") as file:
i = 0
json_data = json.load(file)
for pair in json_data:
pair["source"] = "saket_2018"
pair["pair_id"] = f"{pair['source']}_{i}"
learn_data[pair["pair_id"]] = pair
i += 1
data = pairs_to_vec(learn_data)
assert set(data.negative.columns) == set(default_draco.soft_constraint_names), (
"Feature names do not match."
)
INFO:draco.data_utils:Running 1 partitions of 10 items in parallel on {processes} processes.
/home/runner/work/draco2/draco2/draco/data_utils.py:106: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
return pd.concat(dfs).fillna(0)
INFO:draco.data_utils:Hash of dataframe: 17598251988640889376
project_and_plot(data, test_size=0.3)
Train score: 0.5714285714285714
Dev score: 0.3333333333333333
LinearSVC(C=1, fit_intercept=False)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
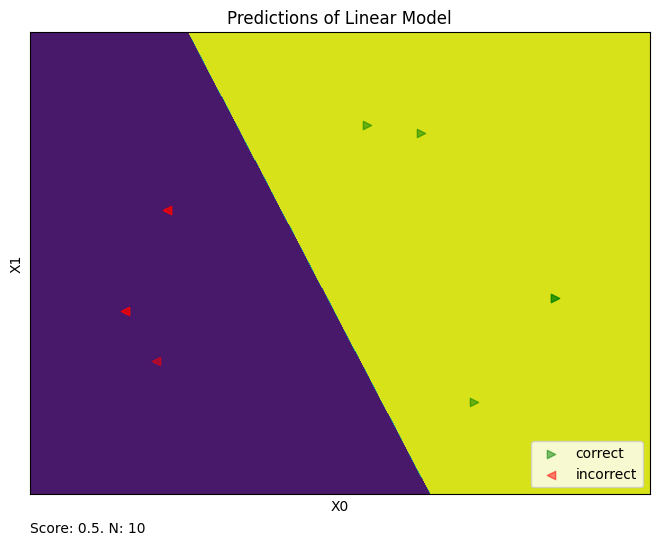
clf = train_and_plot(data, test_size=0.3)
Train score: 1.0
Dev score: 1.0

features = data.negative.columns
new_weights = {}
for feature, weight in zip(features, clf.coef_[0]):
print(f"#const {feature}_weight = {int(weight * 1000)}.")
new_weights[f"{feature}_weight"] = int(weight * 1000)
#const aggregate_weight = 0.
#const aggregate_count_weight = 0.
#const aggregate_group_by_raw_weight = 131.
#const aggregate_max_weight = 0.
#const aggregate_mean_weight = 0.
#const aggregate_median_weight = 0.
#const aggregate_min_weight = 0.
#const aggregate_no_discrete_weight = 131.
#const aggregate_stdev_weight = 0.
#const aggregate_sum_weight = 0.
#const bin_weight = 0.
#const bin_high_weight = 0.
#const bin_low_weight = 0.
#const bin_low_unique_weight = 0.
#const bin_not_linear_weight = 0.
#const binned_orientation_not_x_weight = 0.
#const c_c_area_weight = 0.
#const c_c_line_weight = 371.
#const c_c_point_weight = -240.
#const c_c_text_weight = 0.
#const c_d_col_weight = 0.
#const c_d_no_overlap_area_weight = 0.
#const c_d_no_overlap_bar_weight = -258.
#const c_d_no_overlap_line_weight = -404.
#const c_d_no_overlap_point_weight = 531.
#const c_d_no_overlap_text_weight = 0.
#const c_d_no_overlap_tick_weight = 0.
#const c_d_overlap_area_weight = 0.
#const c_d_overlap_bar_weight = 0.
#const c_d_overlap_line_weight = 0.
#const c_d_overlap_point_weight = 0.
#const c_d_overlap_text_weight = 0.
#const c_d_overlap_tick_weight = 0.
#const cartesian_coordinate_weight = 0.
#const categorical_color_weight = 0.
#const categorical_scale_weight = 0.
#const color_entropy_high_weight = 0.
#const color_entropy_low_weight = 0.
#const continuous_not_zero_weight = 131.
#const continuous_pos_not_zero_weight = 131.
#const count_grt1_weight = 0.
#const cross_zero_weight = 0.
#const d_d_overlap_weight = 0.
#const d_d_point_weight = 0.
#const d_d_rect_weight = 0.
#const d_d_text_weight = 0.
#const date_not_x_weight = 0.
#const date_scale_weight = 0.
#const encoding_weight = 0.
#const encoding_field_weight = 0.
#const facet_col_weight = 0.
#const facet_field_weight = 0.
#const facet_row_weight = 0.
#const facet_used_before_pos_weight = 0.
#const high_cardinality_categorical_grt10_weight = 0.
#const high_cardinality_ordinal_weight = 0.
#const high_cardinality_shape_weight = 0.
#const high_cardinality_size_weight = 0.
#const horizontal_scrolling_col_weight = 0.
#const horizontal_scrolling_x_weight = 0.
#const interesting_color_weight = 0.
#const interesting_column_weight = 0.
#const interesting_detail_weight = 0.
#const interesting_row_weight = 0.
#const interesting_shape_weight = 0.
#const interesting_size_weight = 0.
#const interesting_text_weight = 0.
#const interesting_x_weight = 0.
#const interesting_y_weight = 0.
#const linear_color_weight = 0.
#const linear_scale_weight = 131.
#const linear_size_weight = 0.
#const linear_text_weight = 0.
#const linear_x_weight = 131.
#const linear_y_weight = 0.
#const log_color_weight = 0.
#const log_scale_weight = 0.
#const log_size_weight = 0.
#const log_text_weight = 0.
#const log_x_weight = 0.
#const log_y_weight = 0.
#const multi_non_pos_weight = 0.
#const non_pos_used_before_pos_weight = 0.
#const number_categorical_weight = 0.
#const number_linear_weight = 0.
#const only_discrete_weight = 0.
#const only_y_weight = 0.
#const ordinal_color_weight = 0.
#const ordinal_detail_weight = 0.
#const ordinal_scale_weight = -131.
#const ordinal_shape_weight = 0.
#const ordinal_size_weight = 0.
#const ordinal_text_weight = 0.
#const ordinal_x_weight = -131.
#const ordinal_y_weight = 0.
#const polar_coordinate_weight = 0.
#const position_entropy_weight = 0.
#const same_field_weight = 0.
#const same_field_grt3_weight = 0.
#const size_entropy_high_weight = 0.
#const size_entropy_low_weight = 0.
#const size_not_zero_weight = 0.
#const skew_zero_weight = 0.
#const stack_center_weight = 0.
#const stack_normalize_weight = 0.
#const stack_zero_weight = 0.
#const summary_area_weight = 0.
#const summary_bar_weight = -522.
#const summary_continuous_color_weight = 0.
#const summary_continuous_size_weight = 0.
#const summary_continuous_text_weight = 0.
#const summary_continuous_x_weight = 0.
#const summary_continuous_y_weight = 0.
#const summary_discrete_color_weight = 0.
#const summary_discrete_detail_weight = 0.
#const summary_discrete_shape_weight = 0.
#const summary_discrete_size_weight = 0.
#const summary_discrete_text_weight = 0.
#const summary_discrete_x_weight = 0.
#const summary_discrete_y_weight = 0.
#const summary_facet_weight = 0.
#const summary_line_weight = 361.
#const summary_point_weight = 160.
#const summary_rect_weight = 0.
#const summary_text_weight = 0.
#const summary_tick_weight = 0.
#const value_agg_weight = 0.
#const value_area_weight = 0.
#const value_bar_weight = 263.
#const value_continuous_color_weight = 0.
#const value_continuous_size_weight = 0.
#const value_continuous_text_weight = 0.
#const value_continuous_x_weight = 0.
#const value_continuous_y_weight = 0.
#const value_discrete_color_weight = 0.
#const value_discrete_detail_weight = 0.
#const value_discrete_shape_weight = 0.
#const value_discrete_size_weight = 0.
#const value_discrete_text_weight = 0.
#const value_discrete_x_weight = 0.
#const value_discrete_y_weight = 0.
#const value_line_weight = -394.
#const value_point_weight = 131.
#const value_rect_weight = 0.
#const value_text_weight = 0.
#const value_tick_weight = 0.
#const x_col_weight = 0.
#const x_row_weight = 0.
#const x_y_raw_weight = 0.
#const y_col_weight = 0.
#const y_row_weight = 0.
How to use the learned weights?#
For how to do recomendation with default weights, refer to Visualization Recomendation.
In this example, we use the learned weights above to recommand visualizations.
First, we pass the new learned weights to Draco as following:
from pprint import pprint
from draco import answer_set_to_dict
new_draco = Draco(weights=new_weights)
Then, we can continue with the same procedure as in default Visualization Recommendation. And as you can see, the recommended result from the same input based on the learned weights is different from the one in default.
Note that whether it generates better recommendations or not depends on the examples you learned from.
import importlib.resources as pkg_resources
import draco.asp.examples as examples
hist_spec = pkg_resources.read_text(examples, "histogram.lp")
print("INPUT:")
print(hist_spec)
print("OUTPUT:")
model = next(new_draco.complete_spec(hist_spec))
pprint(answer_set_to_dict(model.answer_set))
print("VIOLATED PREFERENCES:")
pprint(new_draco.count_preferences(str(model)))
INPUT:
attribute(number_rows,root,100).
entity(field,root,(f,0)).
attribute((field,name),(f,0),temp_max).
attribute((field,type),(f,0),number).
attribute((field,unique),(f,0),100).
entity(view,root,(v,0)).
entity(mark,(v,0),(m,0)).
entity(encoding,(m,0),(e,0)).
attribute((encoding,field),(e,0),temp_max).
attribute((encoding,binning),(e,0),10).
#show entity/3.
#show attribute/3.
OUTPUT:
{'field': [{'name': 'temp_max', 'type': 'number', 'unique': 100}],
'number_rows': 100,
'task': 'value',
'view': [{'coordinates': 'cartesian',
'mark': [{'encoding': [{'binning': 10,
'channel': 'detail',
'field': 'temp_max'},
{'aggregate': 'sum',
'channel': 'color',
'field': 'temp_max'},
{'aggregate': 'sum',
'channel': 'x',
'field': 'temp_max'},
{'aggregate': 'count', 'channel': 'y'}],
'type': 'line'},
{'encoding': [{'aggregate': 'sum',
'channel': 'color',
'field': 'temp_max'},
{'binning': 10,
'channel': 'detail',
'field': 'temp_max'},
{'aggregate': 'sum',
'channel': 'x',
'field': 'temp_max'},
{'aggregate': 'count', 'channel': 'y'}],
'type': 'line'},
{'encoding': [{'aggregate': 'sum',
'channel': 'color',
'field': 'temp_max'},
{'channel': 'detail', 'field': 'temp_max'},
{'aggregate': 'sum',
'channel': 'text',
'field': 'temp_max'},
{'aggregate': 'sum',
'channel': 'x',
'field': 'temp_max'}],
'type': 'text'}],
'scale': [{'channel': 'color', 'type': 'ordinal'},
{'channel': 'detail', 'type': 'ordinal'},
{'channel': 'y', 'type': 'linear', 'zero': 'true'},
{'channel': 'text', 'type': 'ordinal'},
{'channel': 'x', 'type': 'ordinal'}]}]}
VIOLATED PREFERENCES:
defaultdict(<class 'int'>,
{'aggregate': 9,
'aggregate_count': 2,
'aggregate_sum': 7,
'bin': 2,
'bin_not_linear': 2,
'c_d_no_overlap_line': 2,
'cartesian_coordinate': 1,
'd_d_text': 1,
'encoding': 12,
'encoding_field': 10,
'high_cardinality_ordinal': 8,
'horizontal_scrolling_x': 3,
'linear_scale': 2,
'linear_y': 2,
'multi_non_pos': 3,
'non_pos_used_before_pos': 1,
'number_linear': 8,
'only_discrete': 1,
'ordinal_color': 3,
'ordinal_detail': 3,
'ordinal_scale': 10,
'ordinal_text': 1,
'ordinal_x': 3,
'same_field_grt3': 1,
'value_agg': 1,
'value_line': 2,
'value_text': 1})