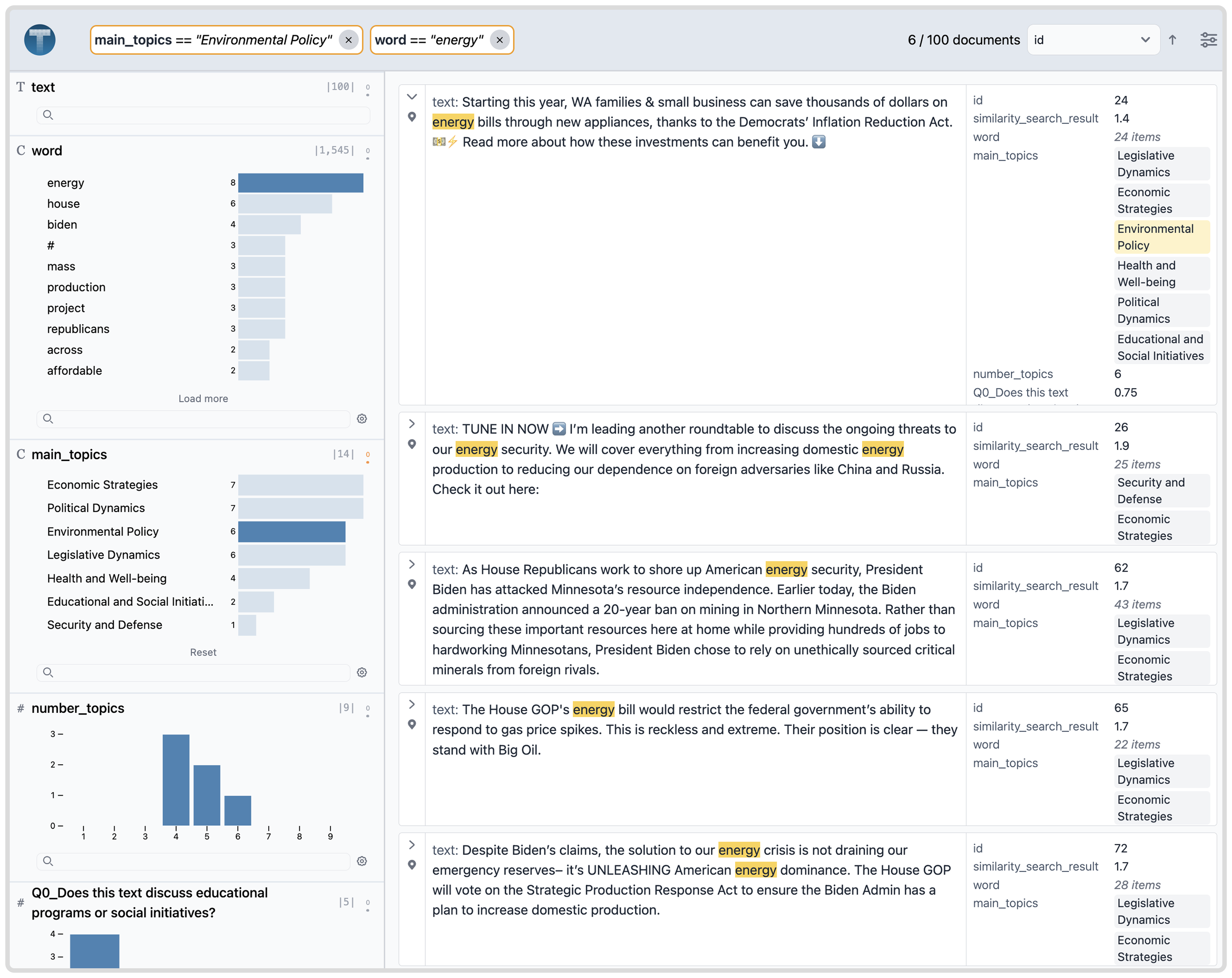
Demo: Social Media Topic Analysis
In this demo, we analyze a dataset of social media posts with concept topics produced using the concept induction algorithm.
python
import pandas as pd
import texture
from texture.models import DatasetSchema, Column, DerivedSchema
P = "https://raw.githubusercontent.com/cmudig/Texture/main/examples/lloom/data/"
df_main = pd.read_parquet(P + "1_main.parquet")
df_word = pd.read_parquet(P + "2_words.parquet")
df_topics = pd.read_parquet(P + "3_topics.parquet")
load_tables = {
"main": df_main,
"words_table": df_word,
"topics_table": df_topics,
}
schema = DatasetSchema(
name="main",
columns=[
Column(name="text", type="text"),
Column(
name="word",
type="categorical",
derivedSchema=DerivedSchema(
is_segment=True,
table_name="words_table",
derived_from="text",
),
),
Column(
name="main_topics",
type="categorical",
derivedSchema=DerivedSchema(
is_segment=False,
table_name="topics_table",
),
),
Column(
name="number_topics",
type="number",
),
Column(
name="Q0_Does this text discuss educational programs or social initiatives?",
type="number",
),
Column(
name="Q1_Does this text condemn violence or advocate for peace?",
type="number",
),
Column(
name="Q2_Is this text focused on remembering victims of violence or atrocities?",
type="number",
),
Column(
name="Q3_Does this text advocate against injustice, racism, or hatred?",
type="number",
),
Column(
name="Q4_Is this text about appreciating law enforcement officers?",
type="number",
),
Column(
name="Q5_Does this text advocate for women's rights or choices?",
type="number",
),
Column(
name="Q6_Is the text focused on the welfare or rights of children?",
type="number",
),
Column(
name="Q7_Does this text discuss political advocacy, viewpoints, or accountability?",
type="number",
),
Column(
name="Q8_Does this text address issues related to health, safety, welfare, or well-being?",
type="number",
),
Column(
name="Q9_Is the focus of this text on environmental or energy issues and policies?",
type="number",
),
Column(
name="Q10_Does this text deal with economic policies, financial matters, or strategies affecting communities or individuals?",
type="number",
),
Column(
name="Q11_Is this text concerned with national security, defense policies, or military affairs?",
type="number",
),
Column(
name="Q12_Does the text discuss healthcare improvements, welfare, or related issues?",
type="number",
),
Column(
name="Q13_Does this text discuss legislative efforts, actions, or conflicts within political parties?",
type="number",
),
],
primary_key=Column(name="id", type="number"),
has_embeddings=True,
has_projection=True,
)
def get_embedding(text):
from openai import OpenAI
client = OpenAI()
text = text.replace("\n", " ")
return (
client.embeddings.create(input=[text], model="text-embedding-3-small")
.data[0]
.embedding
)
texture.run(
schema=schema, load_tables=load_tables, create_new_embedding_func=get_embedding
)